Introduction
A frozen open model that solves 0% of Harvey’s Legal Agent Benchmark end to end is not as weak as that score looks. We left its weights alone and let an automated loop rewrite only the code around it. On a held-out test set the loop never saw, whole-task success went from 0% to 5.0% and criterion pass rate from 63.4% to 80.1%, putting the open model between Sonnet 4.6 and Opus 4.6 on LAB’s headline metric.
Zero model weights changed.
That gain was available because of where these models fail. On LAB (Harvey, 2025), an open model can read the documents, spot the issues, write a sound analysis, then save it to the wrong filename, leave it in a scratch folder, or never write the final file. The judge only reads files at the top of output/ under the exact requested name, so good work can score zero.
The failure is often in the code around the model, the harness (Hugging Face, 2025), not in the legal reasoning. The harness is the runtime wrapper that gives the model tools, feeds it context, executes its tool calls, and decides when the run is finished.
This is what Zhang et al. (2026) call the mismanaged geniuses hypothesis: capable models held back by brittle, hand-built scaffolds, where a weak score can measure the scaffold as much as the model. Hand-engineering a better harness is slow and model-specific, so we automated it: freeze the model and search over the harness.
We ran the Meta-Harness loop (Lee et al., 2026) on deepseek-ai/DeepSeek-V4-Pro. A Claude proposer (Opus 4.8) reads the run history, copies the current best harness, adds one mechanism, and an outer loop keeps it only if it clears a noise margin on a 24-task dev set.
The rest of the post follows the experiment: how the loop rewrote the harness, which fixes moved the score, what transferred across models, and where scaffold changes stopped helping.
A harness is the runtime wrapper around a model: it decides which documents the model reads, which tools it can call, what enters context, how tool calls are executed, and when the run is finished (Hugging Face, 2025). A vanilla harness relays the task prompt and tool calls. A better harness can add a methodology, repair a malformed tool call, or check the output before the run ends. The model weights stay fixed; only the wrapper changes.
Traditionally, this layer is improved by hand: inspect failures, adjust prompts, add checks, change tool wrappers, and run the benchmark again. Meta-Harness automates that loop by giving a coding agent prior harness code, execution traces, and scores, then asking it to propose the next edit (Lee et al., 2026).
- Harvey. (2025). Introducing Harvey’s Legal Agent Benchmark. Harvey blog. https://www.harvey.ai/blog/introducing-harveys-legal-agent-benchmark
- Hugging Face. (2025). Agent Glossary. Hugging Face blog. https://huggingface.co/blog/agent-glossary back: 1, 2
- Lee, Y., Nair, R., Zhang, Q., Lee, K., Khattab, O., & Finn, C. (2026). Meta-Harness: End-to-End Optimization of Model Harnesses. https://arxiv.org/abs/2603.28052 back: 1, 2
- Zhang, A. L., Li, Z., & Khattab, O. (2026). The Mismanaged Geniuses Hypothesis. Blog post. https://alexzhang13.github.io/blog/2026/mgh/
Before the Search: Benchmark, Model, and Baselines
The benchmark (LAB)
Harvey’s Legal Agent Benchmark is a set of realistic legal matters (Harvey, 2025). Each task gives the agent a closed workspace of documents (contracts, emails, spreadsheets, slide decks) and asks for a concrete deliverable: a diligence memo, an issue list, a redline, a draft.
An LLM judge grades the deliverable against a long rubric. It only reads files left at the top level of output/, under the exact requested filename.
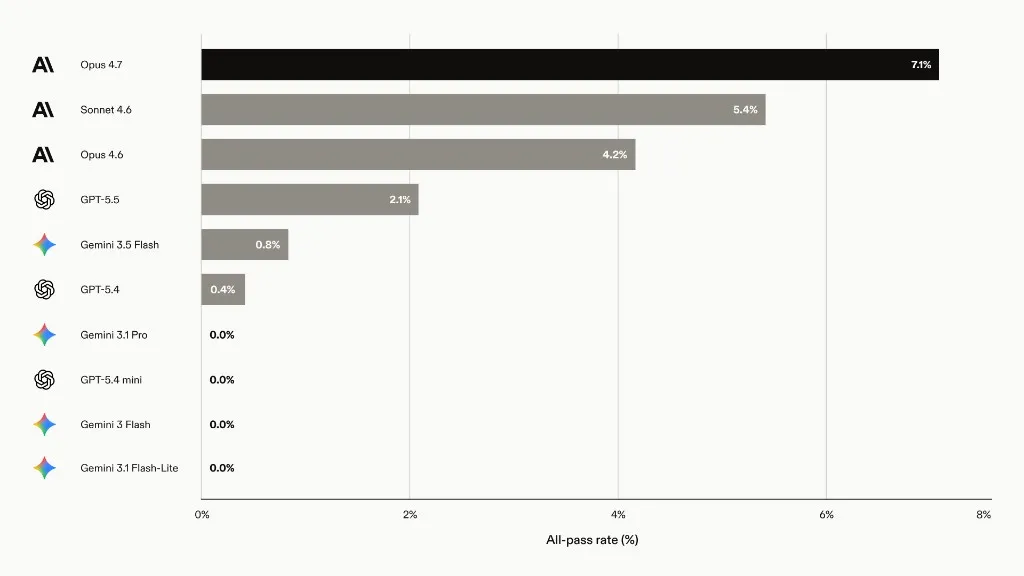
We track two numbers: the pooled criterion pass rate is the fraction of all rubric criteria passed across the run. It is dense and moves smoothly, so we optimize it. The all-pass rate is the fraction of tasks where every criterion passes. That is LAB’s headline number and the one that matters in practice, but on a small set it is sparse and noisy. Even frontier models complete fewer than 10% of these tasks end to end (Harvey, 2025b).
Frontier labs have only recently started reporting legal-work capability. When Anthropic launched Claude Fable 5 in June 2026 (Anthropic, 2026), it was, as far as we know, the first frontier release to put a legal agent benchmark in its headline comparison. LAB was Fable 5’s weakest result by a wide margin.
Legal work is hard even for closed frontier models. Shortly after LAB was introduced, this is where models landed on all-pass (Pereyra, 2026). Apart from Fable 5 (13.3%, not shown here, and pulled from general availability soon after launch), the strongest model finishes only about 7% of tasks end to end. Most of the field sits near zero. That is why harness changes are interesting.
A held-out test split
Harvey does not publish their train/test split (Harvey, 2025c), so we built one over the 1,251 public LAB tasks, pinned to a fixed commit and seed. It has two frozen parts: a 24-task dev set the loop optimizes against (one task per practice area), and a 100-task test set held out for final reporting. The test set tracks the full benchmark’s distribution, then force-includes the hardest case along each “more is harder” dimension: 1.5M tokens, 11 deliverables, 194 rubric criteria, 55 documents. That makes our headline numbers a lower bound.
How the split is built
The test set is filled by a deficit-scoring greedy algorithm that drives several dimensions toward their global proportions at once: practice area, work type, rubric size, and file-type flags (spreadsheet and slide sources, spreadsheet deliverables, email). It then force-includes the extreme of each “more is harder” dimension, including the 1.5M-token matter.
Context size is measured by parsed tokens, not document count: density varies by more than 20x (the 1.5M-token matter has 10 documents; one 55-document task is about 121k tokens), so bucketing by documents would mislead.
The 24-task dev set is a limitation: the loop can only find failure modes that appear in those 24 tasks. The test split checks whether dev wins generalize. We keep dev small because scoring is expensive.
What an evaluation costs
The optimized model is fixed: deepseek-ai/DeepSeek-V4-Pro, served through Hugging Face Inference Providers behind an OpenAI-compatible router. We never fine-tune it, the harness is the only thing that changes. Later we run the resulting harness untouched on other models to test transfer. The judge is separate: claude-sonnet-4-6.
Evaluation has two expensive parts. The agent has to run through long matters, and the judge then makes one Sonnet call per rubric criterion, about 6,300 calls for a 100-task test run. Prompt caching keeps the judge from dominating the dollar bill, but the judge still makes the dev set expensive to scale. A single test run lands around $120 to $160 all-in (roughly $90 to $100 agent rollouts plus $30 to $60 judge calls); a 24-task dev evaluation with 3 trials is in the same range. The 22 evaluated iterations dominate the spend, which is why dev stays small. If scoring is cheap and deterministic, use a much larger dev set.
The cost breakdown
The agent side is roughly $90 to $100 for a 100-task test run: most rollouts exceed a million tokens, and the mean is about 1.8M total tokens per task. A dev evaluation is 72 rollouts (24 tasks times 3 trials) on smaller matters, so its rollout cost is lower but still the same order of magnitude. The judge side is about 6,300 Sonnet calls on test, or about 4,500 on dev. Prompt caching reuses the per-task deliverable prefix across criteria and cuts judge input cost 5 to 8 times, bringing the judge bill to roughly $30 to $60 for a full test run and somewhat less for dev.
The vanilla baseline
With splits fixed, the starting point is the stock LAB harness. On dev it scores 63.1% pooled at 0% all-pass; on held-out test it scores 63.4% at 0%. The zero-score cluster is mostly drafting and multi-deliverable tasks where the model produces no deliverable, an incomplete one, or one the grader cannot find.
The figure shows the baseline by task and practice area. Click an area to expand tasks.
General agent harnesses were worse than vanilla LAB
We also wanted to know whether general-purpose agent harnesses can handle legal work without domain-specific machinery. We compared three open-source agent harnesses under the same conditions.
They did not beat the stock LAB harness. Pi was strongest at 45.4% pooled, but still sat 18.0 points below vanilla LAB and 34.7 points below the optimized frontier. Goose reached 23.2%. mini-swe-agent reached 3.5%. Same model, same judge, same tasks, five very different scores. That is the mismanaged-geniuses hypothesis in numbers.
What went wrong in the external harnesses
Delivery explains a lot of the gap. Pi produced an expected deliverable file type on 75/100 tasks and scored 56.8% on those, but only 11.6% on the 25 tasks where it did not. Goose and mini-swe-agent produced expected file types much less often (26/100 and 7/100).
Timeouts were also part of the harness behavior, not infrastructure exclusions. Goose timed out on 73/100 tasks, Pi on 25/100, and mini-swe-agent on 13/100. Those runs stayed in the aggregate as failures.
Those near-zero tasks and weak general-harness baselines are the opening. With the benchmark and split fixed, we can ask how the optimizer turns missing deliverables into scored work without touching the model.
- Anthropic. (2026). Claude Fable 5 and Claude Mythos 5. Anthropic announcement. https://www.anthropic.com/news/claude-fable-5-mythos-5
- Harvey. (2025a). Introducing Harvey’s Legal Agent Benchmark. Harvey blog. https://www.harvey.ai/blog/introducing-harveys-legal-agent-benchmark
- Harvey. (2025b). Legal Agent Benchmark: Initial Results. Harvey blog. https://www.harvey.ai/blog/legal-agent-benchmark-initial-results
- Harvey. (2025c). Post-training Open Legal Agents with Baseten Research. Harvey blog. https://www.harvey.ai/blog/post-training-open-legal-agents-with-baseten-research
- Pereyra, G. (2026). State of the art on the Legal Agent Benchmark. X (Twitter). https://x.com/gabepereyra/status/2059320727988224128
How the loop works
The loop at a glance
The loop has two jobs. A language model acts as the researcher: it reads the run history, forms a hypothesis, and writes one new mechanism into the harness. A plain Python scaffold acts as the lab: it runs the experiment, scores it on a fixed dev set, and decides whether to keep the change. The model can be creative; the scaffold is strict about what counts.
One pass works like this. The proposer copies the current best harness, adds exactly one mechanism, and checks it on a few dev tasks. It writes a pending_eval.json describing the change. The outer loop re-runs the candidate on all 24 dev tasks, 3 trials each, then promotes it only if its blended score clears the incumbent by one point (min_delta, just above the noise left after averaging three trials). A winner becomes the new best harness.
The protocol and the scaffold
meta_harness.py runs the lab, while SKILL.md tells the proposer how to behave. Two rules matter most.
The first is copy-and-adapt, one mechanism at a time. Each candidate starts as an exact copy of the current best harness, then adds one change. That makes wins compound: once a mechanism is accepted, every later candidate inherits it. The second is no task-specific hints, and never read the test split. A mechanism has to help on unfamiliar matters, not memorize dev.
When the proposer is done, it writes a pending_eval.json: hypothesis, changes, fix_tasks, regression_tasks, and observed evidence. Here is one actual candidate, with long prose fields trimmed.
Example pending_eval.json (one candidate, prose trimmed)
{
"iteration": 5,
"candidates": [
{
"name": "deliverable_reassembly_gate",
"hypothesis": "Reassembling a chunked-write-clobbered deliverable from the model's own write history raises the pooled criterion pass rate: a full-document `write` exceeds the per-message output cap, so the model writes the instrument in sequential chunks, but `write` replaces rather than appends, so the graded file holds only the final fragment while every clobbered chunk survives in the transcript and is deterministically recoverable with zero added model tokens.",
"changes": "Copied the highest not-promoted orphan deliverable_superset_gate to agents/deliverable_reassembly_gate.py (all inherited code byte-identical) and added ONE deterministic post-solve mechanism, _land_clobbered_deliverables: gather the ordered write chunks per deliverable, take the last H1-headed chunk as the head, append the continuation chunks, and land the reassembled document under the exact requested name. Fires only when the graded file is a headless fragment and the reassembly is >= 3x longer. [...]",
"fix_tasks": [
"funds-asset-management/draft-compliance-manual",
"energy-natural-resources/draft-power-purchase-agreement",
"real-estate/draft-purchase-and-sale-agreement",
"insurance/draft-change-of-control-application",
"litigation-dispute-resolution/draft-motion-for-summary-judgment",
"healthcare-life-sciences/draft-management-services-agreement"
],
"regression_tasks": [
"environmental-esg/draft-markup-of-administrative-settlement-agreement",
"immigration/identify-compliance-issues-in-employee-i",
"tax/analyze-section-382-analysis",
"capital-markets/analyze-counterparty-markup-of-underwriting-agreement",
"banking-finance/identify-term-sheet-issues",
"corporate-governance/research-regulatory-approval-requirements"
],
"observed": "Causal proof (deterministic judge re-score of the shipped gate output, no rollout): on the frontier's two cached clobbers the gate recovers funds 0.465 -> 0.921 (+46 criteria) and PPA 0.385 -> 0.912 (+48 criteria), at zero model tokens. Strict additivity: replayed over all 72 cached frontier runs it fires on exactly those 2 and 0 of the other 70. Live A/B: fix slice 0.801 -> 0.914, regression slice flat (0.810 -> 0.805). [...]"
}
]
}
Inside the scaffold and protocol
The proposer runs through propose() on a Claude CLI subscription, with ANTHROPIC_API_KEY stripped for that call and restored for the judge. The judge is thousands of deterministic, metered API calls; the proposer is one multi-hour session the subscription can run unmetered. Because long sessions are fragile, propose() wraps them in auto-resume (_resume_wait) for session-limit resets, timeouts, and transient server errors, but stops on an expired login.
evaluate_harness() benchmarks the candidate on the 24-task dev set at three trials, and update_frontier() decides promotion. _touched_test() rejects any iteration that read the held-out split. _history_digest() feeds the proposer the frontier lineage plus not-promoted orphans, so a mechanism that missed once can be stacked later. loop_state.json keeps one contiguous iteration counter across relaunches.
We copy rather than subclass because after twenty-odd iterations an inheritance chain would be unreadable. A flat copy keeps every mechanism visible in one file. For validation, the protocol asks for either a causal replay (re-run a deterministic fix over old transcripts and re-score) or a pooled comparison over at least 5 fix tasks and 5 regression tasks. Single-trial, single-task swings are noise.
The promotion rule
The promotion rule decides what the loop keeps. That makes its score the thing the search will optimize, for better or worse. A candidate is promoted only if its blended score beats the current frontier by at least one point (min_delta), a margin just above the noise left after averaging three trials.
LAB’s headline all-pass metric is too sparse to optimize directly. On 24 dev tasks at three trials, one extra all-passing rollout is about 1.4 points, so optimizing all-pass directly means chasing luck. We optimize the denser pooled rate and fold all-pass in as a bonus:
score = pooled_criterion_rate + 0.5 * all_pass_rate - 0.005 * tokens_per_million
Each weight has a reason: 0.5 on all-pass means one lucky all-pass run cannot clear the 1% margin by itself, but a pooled gain plus an all-pass gain can. The small cost term (about half a point per million tokens) stops a much more expensive harness from winning on a marginal score gain. update_frontier() recomputes the incumbent under the current weights on every comparison, so changing a weight cannot promote a worse harness at a boundary. The three-trial noise check is in the appendix; the stale-weight bug is in the measurement details.
Background
Using a language model to evolve code or prompts against a metric is now a common pattern. The closest neighbors:
- The mismanaged geniuses hypothesis (Zhang et al., 2026) explains why harness search is worth trying: capable models can look weak when the wrapper mismanages them. Automated harness search acts on that idea: stop hand-tuning the scaffold and search over it.
- Meta-Harness (Lee et al., 2026) is the framework we build on: automated search over the harness around a fixed model, with a language-model proposer and a per-domain verifier. This post applies it to legal agent work.
More neighbors in program and prompt evolution
- AlphaEvolve (Novikov et al., 2025) and OpenEvolve (Sharma, 2025) evolve whole programs against a verifier. They evolve the solution program; we evolve the wrapper around a fixed model.
- ShinkaEvolve (Lange et al., 2025) keeps a population across islands and an archive. We keep one compounding frontier. Simpler, less diverse.
- The Darwin Gödel Machine (J. Zhang et al., 2025) rewrites its own code; we constrain edits to the harness layer.
- GEPA (Agrawal et al., 2025) evolves prompts against a Pareto frontier; we push the same reflect-mutate-keep loop into harness code.
- Karpathy’s autoresearch (Karpathy, 2026) has an agent edit one file and keep or discard by an overnight metric. Our
SKILL.mdplays the role ofprogram.md; our experiment is an expensive LLM-judged eval, not a short training run.
What we add is the work needed to run this on a hard, expensive domain: provider failover, a prompt-caching judge, a reproducible split, the blended objective above, and enough reliability for a subscription proposer to run unattended. With the loop defined, we can ask what it actually learned to fix.
- Agrawal, L. A., Tan, S., Soylu, D., Ziems, N., Khare, R., Opsahl-Ong, K., Singhvi, A., Shandilya, H., Ryan, M. J., Jiang, M., Potts, C., Sen, K., Dimakis, A. G., Stoica, I., Klein, D., Zaharia, M., & Khattab, O. (2025). GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning. https://arxiv.org/abs/2507.19457
- Karpathy, A. (2026). autoresearch: AI agents running research on single-GPU nanochat training automatically. GitHub repository. https://github.com/karpathy/autoresearch
- Lange, R. T., Imajuku, Y., & Cetin, E. (2025). ShinkaEvolve: Towards Open-Ended and Sample-Efficient Program Evolution. https://arxiv.org/abs/2509.19349
- Lee, Y., Nair, R., Zhang, Q., Lee, K., Khattab, O., & Finn, C. (2026). Meta-Harness: End-to-End Optimization of Model Harnesses. https://arxiv.org/abs/2603.28052
- Novikov, A., Vũ, N., Eisenberger, M., Dupont, E., Huang, P.-S., Wagner, A. Z., Shirobokov, S., Kozlovskii, B., Ruiz, F. J. R., Mehrabian, A., Kumar, M. P., See, A., Chaudhuri, S., Holland, G., Davies, A., Nowozin, S., Kohli, P., & Balog, M. (2025). AlphaEvolve: A coding agent for scientific and algorithmic discovery. https://arxiv.org/abs/2506.13131
- Sharma, A. (2025). OpenEvolve: an open-source evolutionary coding agent. GitHub. https://github.com/algorithmicsuperintelligence/openevolve
- Zhang, A. L., Li, Z., & Khattab, O. (2026). The Mismanaged Geniuses Hypothesis. Blog post. https://alexzhang13.github.io/blog/2026/mgh/
- Zhang, J., Hu, S., Lu, C., Lange, R. T., & Clune, J. (2025). Darwin Gödel Machine: Open-Ended Evolution of Self-Improving Agents. https://arxiv.org/abs/2505.22954
Results
The dev frontier moved in a few big steps
This chart shows the optimization run on the 24-task dev set. Each dot is one candidate harness the loop evaluated. The y-axis is pooled criterion pass rate, the dense score we optimize. Filled dots are candidates that became the new best harness. Hollow dots are candidates that were tested and rejected. The step line is the frontier, the best score seen so far.
The frontier moves in a few jumps, not a steady slope. Most candidates do not clear the promotion rule. The biggest jump is deliverable_landing_gate, which moves dev pooled from 72.8% to 79.2% by putting deliverables where the judge can find them. The final frontier reaches 83.3% pooled and 4.2% all-pass, up 20.2 points from vanilla.
The biggest gains came from file handling, not prompts
The next chart shows every candidate: cost (mean tokens per run) against dev score, colored by mechanism type.
The candidates fall into four families:
- Deliverable landing and delivery (code). The largest gain came from putting files where the judge expects them. The judge only loads files at the top level of
output/under the exact requested name, and the model often leaves the deliverable misplaced, misnamed, chunked, or in a scratch folder. A deterministic post-solve step lands the right file with zero extra model tokens and turns a near-zero score into a scored result. - Matter fidelity (code). On long-context tasks, the workspace can contain a distractor matter, and the model sometimes drafts a strong answer about the wrong dispute. A runtime check detects that wrong-matter draft and forces a redraft; with a small best-of-N vote,
matter_audit_allworkbecame the final frontier. - Loop robustness (code). Repair provider-corrupted tool calls (
toolcall_json_repair) and break repetition loops. These changes were few, but they helped other model families too because they fix execution failures rather than DeepSeek-specific behavior. - Prompt playbooks (prompt). Work-type methodology in the system prompt, for analysis, drafting, and redlining. The first prompt playbooks entered the frontier early; later prompt-only candidates did not beat the code-heavy frontier.
Five of the top six harnesses are deterministic code, not prompt edits. For a weak agent, a lot of “capability” is I/O discipline the scaffold can guarantee. Harvey’s own harness-engineering write-up landed on the same idea, with stop hooks that validate deliverables before a run ends (Artificial Lawyer, 2026).
The heatmap shows the same story broken out by task, and the gains are far from uniform. Some rows start strong and barely move, while others, especially drafting and multi-deliverable tasks, sit near zero until the file-landing fix or matter audit arrives, then jump in one step. That is copy-and-adapt doing useful work: one observed failure mode fixed, then kept while the next mechanism is added.
Code fixes transferred; prompt playbooks did not
The harness was tuned only on DeepSeek-V4-Pro. To test whether it generalizes, we ran one harness, the mid-lineage deliverable_landing_gate, untouched on each model and on the same held-out split.
Within the same family the harness transfers well: DeepSeek V4 Flash gains 14.4 points, about what the tuned model gets from deliverable_landing_gate. Nemotron-3 Ultra, a different family, barely moves at +0.4 points. That average hides two canceling effects: toolcall_json_repair clears Nemotron’s tool-call crashes, while DeepSeek-tuned prompt playbooks hurt tasks Nemotron can already finish. Robustness and code mechanisms transfer across families; prompt playbooks are model-specific and can backfire.
Where scaffold fixes stopped helping
The run does not climb forever. The top candidates cluster around 83% pooled, and the matter-audit plus deliverable-landing family looks like a local ceiling for the search we ran. That is not proof that prompting is exhausted. As the candidate landscape shows, the loop evaluated 4 prompt-only candidates, 14 code-only candidates, and 1 mixed candidate. Two prompt playbooks entered the frontier early, so prompting can help; the proposer simply spent more of the run exploring scaffold code.
The remaining misses look harder. The tax Section 382 task, for example, misses roughly 30 of 107 criteria on every trial, mostly quantitative depth and citation precision. A better prompt may still recover some of that. But at some point the wrapper runs out of tricks, and the base model has to carry the substantive work.
- Artificial Lawyer. (2026). Harvey Drives Legal Agent Learning via Harness Engineering. Artificial Lawyer. https://www.artificiallawyer.com/2026/04/07/harvey-drives-legal-agent-learning-via-harness-engineering/
Conclusion
What the loop reliably finds
The result is bounded, but not small. Holding an open model fixed and letting a loop rewrite only the harness moved DeepSeek-V4-Pro from 63.1% to 83.3% on dev and, untouched, from 63.4% to 80.1% on held-out test. Zero weights changed. Read through the mismanaged-geniuses lens, the vanilla score understated the model: much of the gap was the scaffold, and search closed most of it (Zhang et al., 2026).
The external-harness comparison says the same thing from another angle: with the same model and judge, different wrappers ranged from 3.5% to 80.1% pooled.
The loop was best at fixing operational failures: deliverables in the wrong place, provider-corrupted tool calls, repeated loops, and drafts about the wrong matter. The largest later gains came from scaffold code because those failures were easy for code to pin down. Prompting was not useless: two prompt playbooks entered the frontier early, and the proposer simply tried fewer prompt-only changes. The remaining failures likely need some mix of better prompts, better tools, and a stronger base model.
What’s next
A few next steps follow from the failure modes that remain.
- A cheaper judge, then a bigger dev set. A cheaper model calibrated to Sonnet, with Sonnet validating final results, could make the judge much cheaper. For example, Sonnet 4.6 is listed at $3/M input and $15/M output (Anthropic, 2026), while DeepSeek V4 Flash is $0.14/M input and $0.28/M output (DeepSeek, 2026), about 21x cheaper on input and 54x cheaper on output. A cheaper judge could grow the dev set by an order of magnitude, which may expose failure modes the current 24-task set never shows.
- Other hard benchmarks. Start with rubric-graded legal benchmarks, LEXam (Fan et al., 2025) and PLawBench (Shi et al., 2026), then try very different domains like Humanity’s Last Exam (Phan & others, 2025) and CritPt (Zhu et al., 2025). CritPt is the sharp test because it already has a strong hand-built harness, PhysicsIntern (Louapre et al., 2026) (Gemini 3.1 Pro 17.7% to 31.4%).
- A population instead of one frontier. We keep one compounding best harness. ShinkaEvolve (Lange et al., 2025), AlphaEvolve (Novikov et al., 2025), and the Darwin Gödel Machine (J. Zhang et al., 2025) keep diverse populations, which could preserve mechanisms that look weak alone but combine well.
- Tools and prompts for the ceiling. More prompt search may still help on substantive tasks. Some misses need new tools too: web search for legal research, and code for dollar reconciliation, date timelines, and spreadsheet parsing.
This fits a broader pattern: language models make capable researchers when you put them in a loop with a good verifier. The artifact might be a training script (Karpathy, 2026), a program (Lange et al., 2025; Novikov et al., 2025), prompts (Agrawal et al., 2025), an agent’s own code (J. Zhang et al., 2025), or a harness around a fixed model (Lee et al., 2026). The verifier is the hard part. Coding and competition math have deterministic checkers; law mostly did not. LAB’s rubric, scored criterion by criterion by an LLM judge, is not perfect, but it is dense enough for search to climb.
Automated harness search is a practical way to test the mismanaged-geniuses bet (A. L. Zhang et al., 2026). Instead of training a bigger model, stop handicapping the one you have, then measure how much weakness was never the model’s fault. On legal-agent work, the gain from plumbing alone is a strong sign that the model was mismanaged, not outmatched.
We release the LAB harness code on GitHub. We also publish the run artifacts in a Hugging Face Bucket, including dev and test results plus proposer traces.
Acknowledgements
Thanks to Leandro von Werra and Lewis Tunstall for useful feedback on earlier drafts.
- Agrawal, L. A., Tan, S., Soylu, D., Ziems, N., Khare, R., Opsahl-Ong, K., Singhvi, A., Shandilya, H., Ryan, M. J., Jiang, M., Potts, C., Sen, K., Dimakis, A. G., Stoica, I., Klein, D., Zaharia, M., & Khattab, O. (2025). GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning. https://arxiv.org/abs/2507.19457
- Anthropic. (2026). Pricing. Claude Platform Docs. https://platform.claude.com/docs/en/about-claude/pricing
- DeepSeek. (2026). Models and Pricing. API documentation. https://api-docs.deepseek.com/quick_start/pricing
- Fan, Y., Ni, J., Merane, J., Hermstrüwer, Y., Huang, Y., Akhtar, M., Salimbeni, E., Leippold, M., Sachan, M., Stremitzer, A., Engel, C., Ash, E., & Niklaus, J. (2025). LEXam: Benchmarking Legal Reasoning on 340 Law Exams. https://arxiv.org/abs/2505.12864
- Karpathy, A. (2026). autoresearch: AI agents running research on single-GPU nanochat training automatically. GitHub repository. https://github.com/karpathy/autoresearch
- Lange, R. T., Imajuku, Y., & Cetin, E. (2025). ShinkaEvolve: Towards Open-Ended and Sample-Efficient Program Evolution. https://arxiv.org/abs/2509.19349 back: 1, 2
- Lee, Y., Nair, R., Zhang, Q., Lee, K., Khattab, O., & Finn, C. (2026). Meta-Harness: End-to-End Optimization of Model Harnesses. https://arxiv.org/abs/2603.28052
- Louapre, D., Niklaus, J., & Tunstall, L. (2026). physics-intern: an autonomous agentic framework for physics research. https://huggingface.co/spaces/huggingface/physics-intern
- Novikov, A., Vũ, N., Eisenberger, M., Dupont, E., Huang, P.-S., Wagner, A. Z., Shirobokov, S., Kozlovskii, B., Ruiz, F. J. R., Mehrabian, A., Kumar, M. P., See, A., Chaudhuri, S., Holland, G., Davies, A., Nowozin, S., Kohli, P., & Balog, M. (2025). AlphaEvolve: A coding agent for scientific and algorithmic discovery. https://arxiv.org/abs/2506.13131 back: 1, 2
- Phan, L., & others. (2025). Humanity’s Last Exam. https://arxiv.org/abs/2501.14249
- Shi, Y., Liu, H., Hu, Y., & others. (2026). PLawBench: A Rubric-Based Benchmark for Evaluating LLMs in Real-World Legal Practice. https://arxiv.org/abs/2601.16669
- Zhang, A. L., Li, Z., & Khattab, O. (2026). The Mismanaged Geniuses Hypothesis. Blog post. https://alexzhang13.github.io/blog/2026/mgh/ back: 1, 2
- Zhang, J., Hu, S., Lu, C., Lange, R. T., & Clune, J. (2025). Darwin Gödel Machine: Open-Ended Evolution of Self-Improving Agents. https://arxiv.org/abs/2505.22954 back: 1, 2
- Zhu, M., Tian, M., & others. (2025). Probing the Critical Point (CritPt) of AI Reasoning: a Frontier Physics Research Benchmark. https://arxiv.org/abs/2509.26574
Appendix
Why three trials
Running each candidate three times per task triples cost, but buys signal. Aggregate pooled rate is stable; individual tasks are not. One trial can collapse to 0% from a provider error or missing deliverable, enough to flip a promotion on 24 tasks. Averaging three trials cuts per-harness noise to about 0.8 points, which makes the 1-point margin usable.
Across all tasks, the three single passes land at 72.9%, 76.2%, and 74.9% (mean 74.7%, std 1.4 points), so a single pass is fine for a large-split headline. Per task, no: a couple of tasks have one trial at 0% while the others sit near 80%. Averaging three trials cuts noise from about 1.4 to 0.8 points (standard deviation over the square root of three), and the 1-point margin sits just above that. A stricter 3-point margin blocked genuine stacked gains of 1.5 to 1.8 points and wasted proposer sessions. One point lets directional gains compound while still rejecting single-pass noise.
Measurement and reliability details
The loop worked before it was trustworthy. It lost iterations to crashes, sometimes promoted the wrong harness, measured some models unfairly, and left a record nobody could read. Candidate generation was the easy part. The hard part was making the measurement hold up: survive crashes, score correctly, and measure every model the same way.
A promotion-rule bug (the cost-λ boundary)
The clearest example was a bug in the promotion rule. At one point deliverable_finish_guard got promoted even though it was worse than deliverable_landing_gate on every axis: lower pooled, lower all-pass, more tokens. It should have been rejected.
The cause was a stale number. The rule compared the challenger’s fresh cost-adjusted score against the incumbent’s stored score, but that stored score came from an earlier run with a different cost weight. The comparison was apples to oranges.
The fix is the rule now followed by update_frontier(): recompute the incumbent under the current weights, never trust a stored derived number. Copy-and-adapt also saved us. The mistaken promotion did no lasting damage because the finish-guard mechanism was carried into the next candidate and is still in the final frontier. A forgiving search structure absorbs some bad decisions.
Provider reliability as a first-class variable
Through a hosted router, infrastructure flakiness kept looking like model failure. Long rollouts (minutes each, up to a couple million tokens) hit stream drops, protocol errors, and rate limits, so we added provider failover and per-provider retries. The starkest case: Nemotron first scored about 1 out of 100 because the adapter did not retry a bare server error on the first turn. Most runs died at turn zero. A one-line fix turned “this model cannot do legal work” into a fair measurement.
That is why we re-ran transient provider failures before reporting test numbers. Every remaining zero should be a model or harness failure, not an infrastructure artifact.
Hardening the LLM as an optimizer
The proposer is a Claude subscription session that runs one to three hours per iteration. Keeping it alive took more work than expected. It auto-resumes on recoverable interruptions (session-limit resets, timeouts, transient server errors) and stops cleanly on unrecoverable ones, like an expired login. We learned that after losing three iterations to silent auth failures. A process-group kill prevents orphaned rollout subprocesses, and the leakage audit rejects any iteration that touched the held-out split.
An LLM optimizer needs the same operational hardening as any long-running distributed job: retries, idempotent resume, clean failure, and a guard against contaminating held-out data. Without that plumbing, the headline number would not hold up.